Unpacking AI
What's the goal of this post. What do you want to tell the reader explicitly so that they can decide if they want to read it?
This post explores the foundations of AI systems by unpacking the concepts of language, intelligence and AI models. We'll examine how Large Language Models (LLMs) work, their mathematical underpinnings, and the progression toward reasoning capabilities. Whether you're new to AI or looking to deepen your understanding of these systems, this guide will help clarify the principles of how these modern AI models are built.
Language, Intelligence and Consciousnesss
We need first define the terms on which we are building our understanding of AI.
Language: is a cultural trait and a tool for collaboration and reasoning which emerged when humans started living in groups. [CITE here]
Intelligence refers to the capacity to achieve complex goals in variable environments, primarily through reasoning, learning, and adaptation.
[dennett2017bacteria]Why consciousness? We don't talk about it in this post?
Modelling basics
A Model is an abstract representation of real-world phenomena. We use models to represent various tools and theories to test our understanding or simulate some phenomena so as to make conjectures about the unknown (prediction).
Statistical model
When we use methods from statistics, to build a model, we make assumptions about the data and the relationships between different observable variables. A statistical model is a mathematical representation of observed data that takes into account the uncertainty and relationships between these (random) variables. (Savage 1954). A Probablistic model is a subset of statistical models that focuses explicitly on using probability distributions to model uncertainty in our observations and data (Hastie et al 2001).
One kind of reader might be overloaded with the terminology already, wheras a familiar one would already skip this section. Maybe I can add an example to make it more clear to the first group.
Machine learning modelling
A model is defined by a set of parameters. When we say learning how to model an observable phenomena, we mean are focusing on finding out the values of these parameters that makes the predictions from our model consistent with the observation we have in reality. As an example, you can think of a typical model as some function which takes some input and produces some output , i.e., our model is some function that maps . [Tie to the previous example] How the function transforms input to output is defined by the class of mathematical functions (linear, polynomial, non-linear, etc.) and the parameters of the function .
But, how do we find the values of the parameters that makes our model realistic? The process of finding the values of that makes our model realistic is called training the model.
The goal of model is to make predictions via the learned function for any new input that we might encounter . This process is called inference or prediction.
Language Models
We are not interested in a figuring out the rules of the language, but rather a model that can use language with the same proficiency as a human, i.e., we want a model that can make predictions about what words and sentence to use in a given context, so as to have a conversation as well as a human does.
Probabilistic Model of Language
In order to build some language model, we need a probabilistic model that can predict what word to generate based on the current prediction and the context. Formally, a language with words in its vocabulary, a language model tries to model: , where:
- denotes a word in the document at position in the response with being the total length of the response,
- denotes the parameters of the model,
- represents all words before position .
This is a model that sequentially predicts the next word in the response conditioned on the previous generated words.
Generative Model
Technically, the above model of predicting one word at a time and building a response based on the previous predictions is a class of machine learning models called auto-regressive models. An auto-regressive model represents conditional probability distribution of next word .
This allows that the model can generate a response by sampling from the predicted probability distribution of the next word in a sequential manner, where the next word prediction is based on the responses sampled so far. This is an exmaple of a generative model as it can generate a response (or data) by sampling from the probability distribution of the next word (Shannon 1948).
How to build a language model?
ML Modelling Basics
Consider that you're trying to build a model that can classify if a given image is of a dog or cat. You want a model that you can use to make predictions on unseen data and make accurate predictions (classfications in this case). The main idea is that we need a probabilistic model that can evaluate the likelihood of a given image being of a dog or cat based on some existing dataset of training images of dogs and cats along with their corresponding labels.
Formally, we want a model that can give us the probability of a given image being of a dog or cat , where is the image and is the label.
How do we build this model, and how do we know if it's any good? To build such model, we need:
- training data: some data from which we can learn the parameters of the model - in this case, a dataset of images of dogs and cats along with their corresponding labels.
- evaluation metric: a function that we can use to evaluate how well our model will do on unseen data - in this case, accuracy on some held out dataset.
- modelling technique: a mathematical parameterized function or archtecture that we want to fit on this training data and learn the parameters - in this case, a neural network, a decision tree, etc.
A similar process is used to also build a large language model where the task is to model all the language on the internet itself. We need these three components: modelling technique (LLMs/transformers), data (from the internet) and some loss or measure (similar to accuracy). Let's unpack each of these components.
Measures:
Cross-entropy:
Cross-entropy, a concept from information theory, measures the divergence between two probability distributions. Mathematically, it is defined for two discrete distributions: P, representing the actual data distribution, and Q, the model's predicted distribution, as follows:
The lower the cross-entropy, the better the model aligns with the true distribution. Consequently, cross-entropy acts as a training or loss function, directing the model to modify its parameters for improved predictions. By reducing cross-entropy, LLMs enhance their ability to generate text that is coherent and contextually appropriate, closely to the one they found in their training data (human).
Perplexity:
There's also another important measure that we use to evaluate the performance of a language model. Formally in information theory, perplexity is a measure of uncertainty in the value of a sample from a discrete probability distribution [CITE]. In the context of modelling language, we care about Perplexity per token (PPL) which is measure that gives an idea of how efficiently you can compress the language with some probabilistic model. It does so by mapping probability distribution to the average number of bits it would take to represent that distribution, . Inutitively, this represents the average number of bits needed per word to model the language using this particular model. Eg, if PPL is 1, that means avg num of bits per token are 0, which means the model has no uncertainty about the answer and either the language is deterministic or the model can accurately predict all the time. On the other hand, if PPL is V, that means the model is uniform about its predictions for the next word and is doing a poor job of modelling the language. PPL correlates with how well a given language model can be used on unseen downstream tasks.
Transformers
Transformers are a type of neural network that can capture long term dependencies and relationships between words in sequences. In order to keep the track of all the previous words you have encountered and finding the relevant ones, transformers use a technique called attention. You can think of it as a key-value cache or memory that keeps track of previous words and can be used to find relationships between words. [CITE] At a high level, Transformers are big neural networks with lots of parameters that use this attention mechanism to learn the relationships between words for making relevant next word predictions.
Why they are called Large Language Models? Well, the higher the number of parameters in a model, the more capacity to learn they have (given they have equivalently large data to learn from). This is sometimes referred as scaling the model. This can be done via either increasing the number of parameters (size) or training the models for a longer amount of time (compute) [CITE]. Here are the classic scaling laws for
You can think of y-axis as the performance on unseen data, i.e., a proxy for the modelling quality or intelligence of the model - the lower the better. And you can think of x-axis as resources (compute, data, model size). The above figure essentially shows that the intelligence of the model scales with the resources you throw at it.
This is not just limited to the scaling law or cross-entropy, but also the perplexity during training. In the fig below [CITE], perplexity goes down with using a bigger model (higher num of parameters) as seen in Llama training curves.
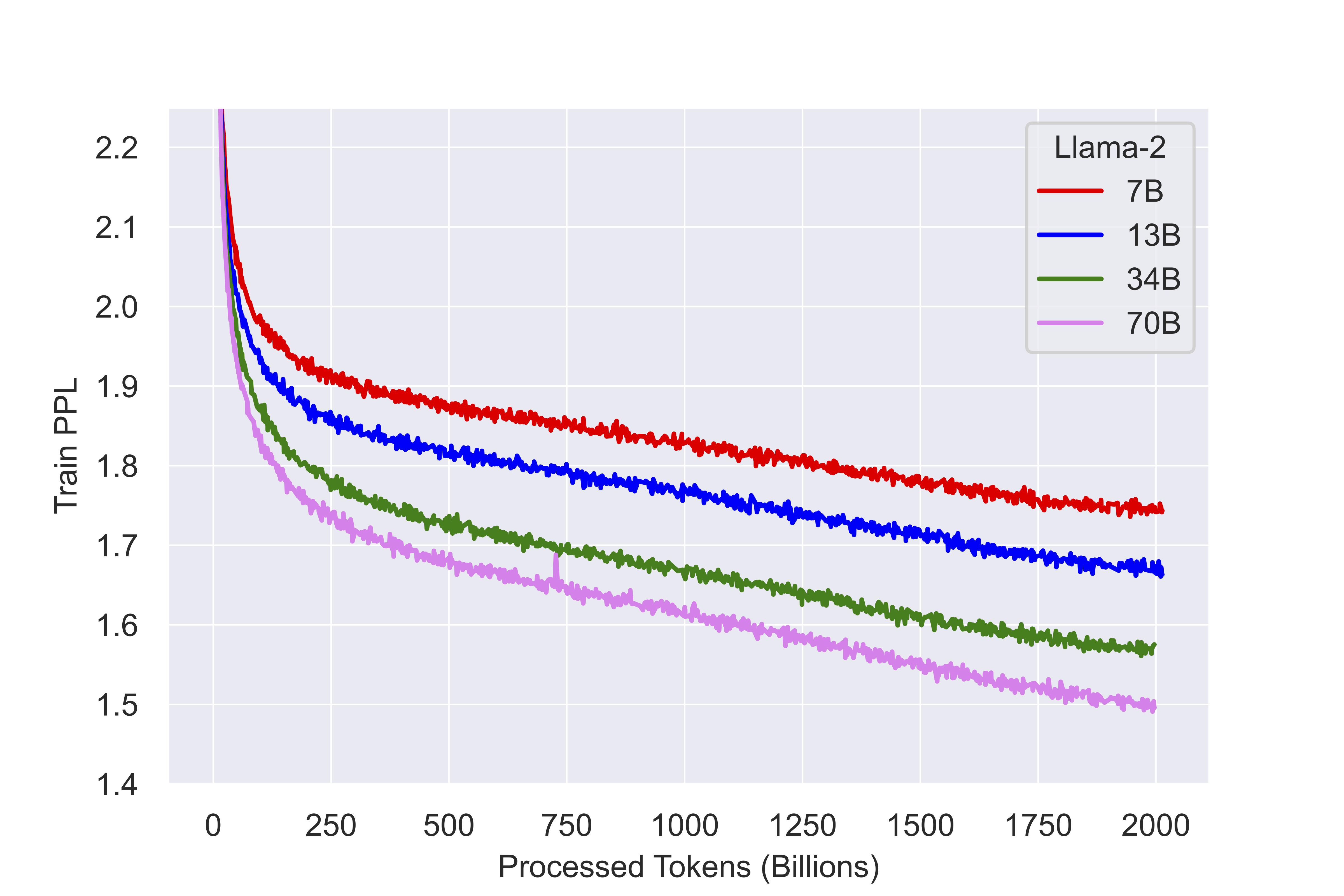
[This image doesn't look good - need to fix it!]
Data (Internet)
As we saw above, the more data and compute you throw at a model, the better it is at modelling language. Therefore, the current paradigm is to use as much data as possible to train the model - scraping the internet and training the model on that.
However, we are now in a setting where we have exhausted our data reserves - already used most of the free data on internet for training. This is where the frontier lies currently - how do we get past this barrier? While different approaches are being explored - using synthetic data, purchasing data, hiring more people to label data, etc. - one of the main focus is on the reasoning capabilities of the model. We will explore this in the next section, but before that, here's the recap of the recipe for building a large language model:
LLM Recipe
- Step 1: Unsupervised Pre-training Train the transformer model on a massive corpus of text data from the internet using for next word prediction task using a cross-entropy like loss function. The goal here is to learn a model that learns the statistical properties of the language, facts about the world, and other patterns in the data.
- Step 2: Supervised Fine-tuning (SFT) Another round of training the model obtained from previous step, but this time on quality human-annotated datasets (like question-answering, translation, or coding tasks) with the similar cross-entropy like objective to get a fine-tuned model. The goal here is to learn a model that does better on these tasks and focuses more on the quality of responses that are consistent with the human responses in the dataset. (GPT-2/3)
- Step 3: Reinforcement Learning from Human Feedback (RLHF) Here the model is further refined using a reinforcement learning objective, which involves having a dataset of human preferences between responses. This allows the model to be better aligned at matching the human preferences and qualitative human judgments, enhancing its ability to make more satisfactory responses to users’ queries. (GPT-3.5/4)
The above recipe contains a few steps that we didn't talk about. The SFT step is like the unsupervised pre-training step, but done on quality human-annotated and task-specific datasets. The RLHF step is like the supervised fine-tuning step, but done on human preferences dataset, with a different loss function and optimization technique.
Reasoning
To mention RL, and Chain of Thought (CoT) before diving in here!
- RL - trial and error
- CoT - model also outputs it's reasoning/thinking process
As mentioned above, we're running out of data to train on. A new category of methods are using the test-time compute to build models that can reason during the inference time and use that reasoning to make better predictions. OpenAI's o1/o3 models, xAI's Grok, and DeepSeek's R1 are some of the recent models that use this approach - where they call thinking or reasoning as using the test-time compute to generate a response. The main idea is to use Reinforcement Learning (RL) with the chain of thought (CoT) prompting technique to create a model that can learn to leverage the response from the chain of thought process to do reasoning about the given input and generate a response. This allows the model the ability to use a longer chain of thought response via increasing the test-time compute to generate a better response, hence this is also called test-time scaling.
Here's an example of how test-time scaling looks like on a few reasoning tasks from [CITE]:
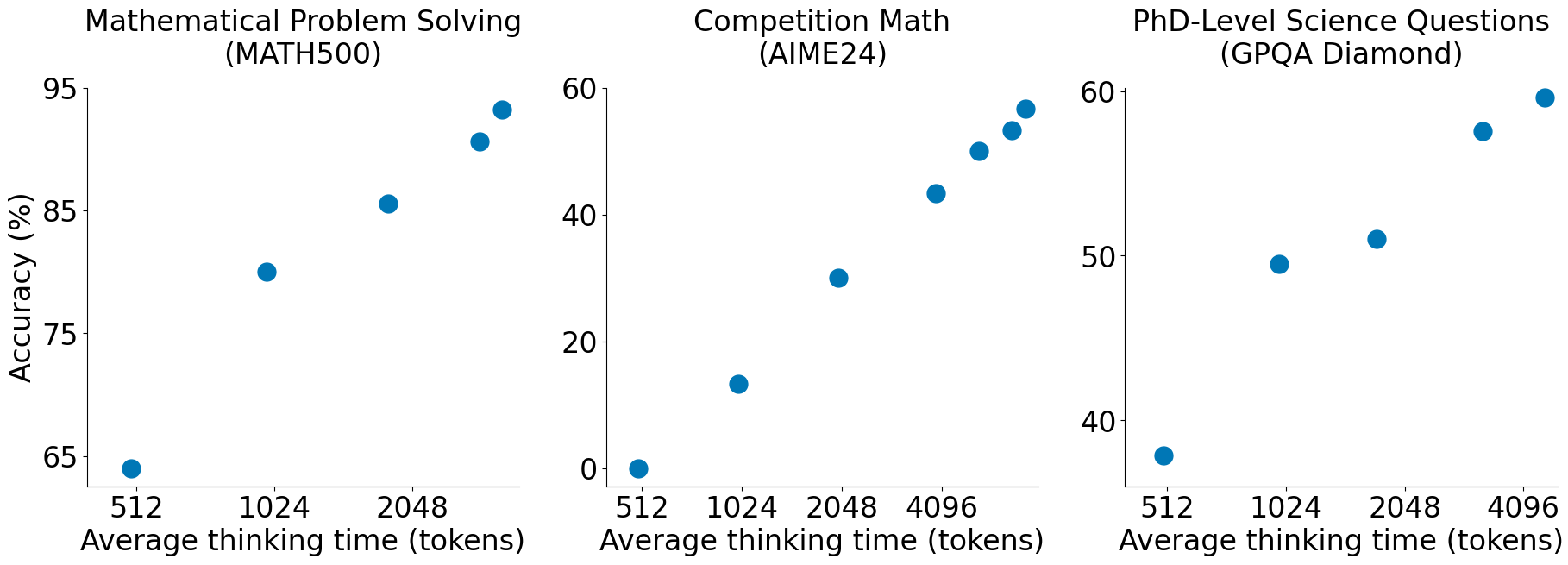
In the above figure, the higher the number of tokens, i.e., the longer the chain of thought response, the better the model gets at reasoning.
Recently, DeepSeek R1 (DeepSeek-AI et al., 2025) has successfully replicated o1-level performance, also employing reinforcement learning via millions of samples and multiple training stages and shared the recipe for builiding such a reasoning model. The intersting part is that they achieve that without using any human-annoted preference data (no RLHF step) and instead relying on the use of RL optimization technique to build such a reasoning model.
We will now briefly describe the recipe for building a reasoning model as described in the DeepSeek R1 paper that matches the o1 level of performance, purely via using a RL based post-training step.
DeepSeek recipe
Disclaimer: We will illustrate the recipe with the DeepSeek R1-Zero model, a simpler version (less powerful) than the R1 model, but still matches the o1 level of performance, to demostrate the core idea about how to build such a reasoning model.
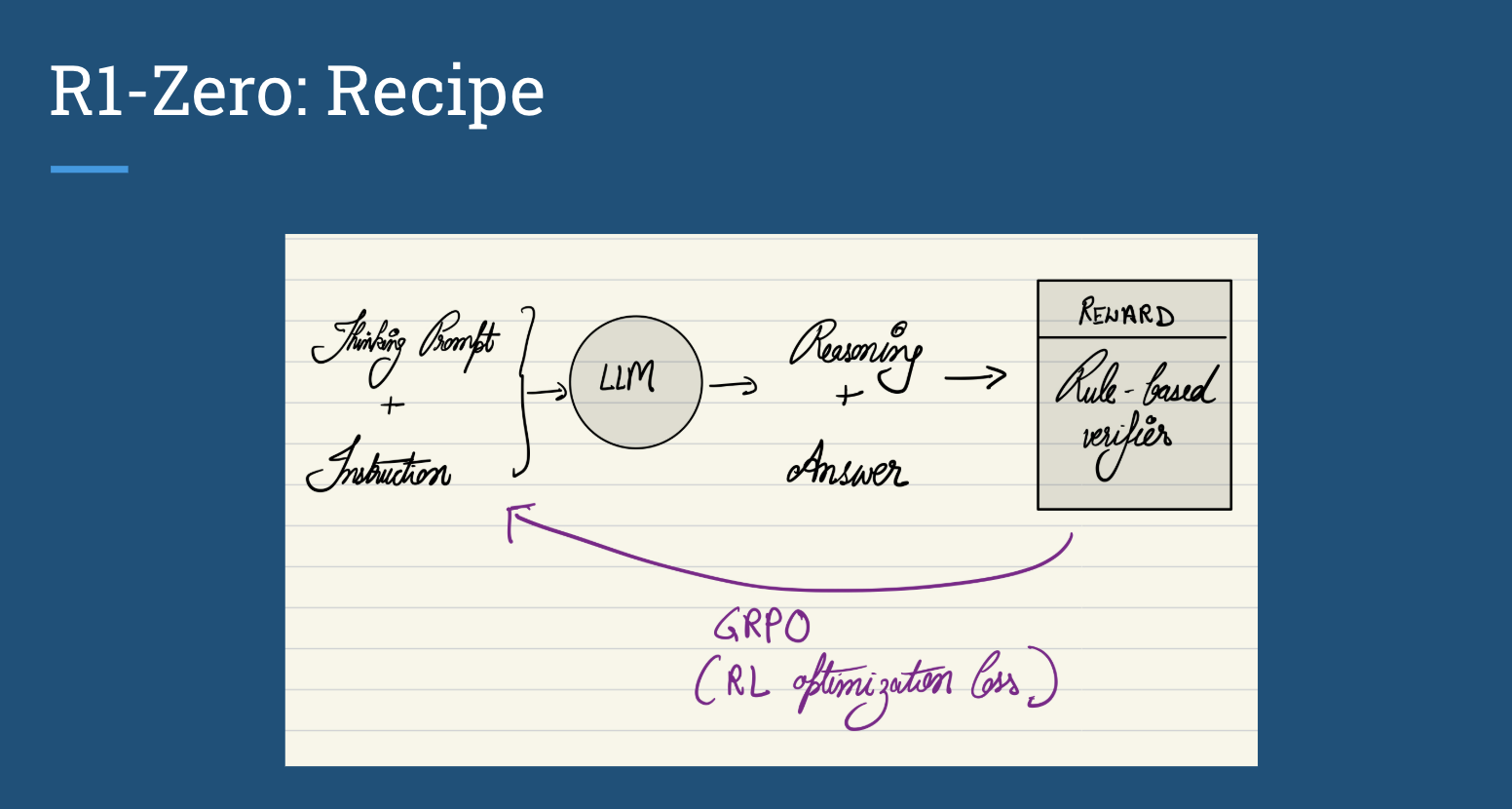
The THINKING prompt
The THINKING or REASONING process is triggered by a special prompt, much like the CoT prompting technique, that gives the model the affordance to think and generate a longer chain of reasoning responses.

The RL step
The core of the trial and error process is done via access to some reward function that can evaluate the quality of the response. In their case, they use rule-based verifiers and symbolic checkers, like actually computationally solving the math problems, checking for compilation errors, or manually providing unit-tests, or even some heuristics (like linting style guide). This gives the optimization process to evaluate the quality of the response and guide the model to generate a response that is more likely to be correct - sidestepping the need for any human-annoted preference data.
The actual optimization is guided by a RL-based optimization objectice that allows us to learn the weights of the model in a way that it maximizes the reward function.
The below figure how this optimiztion process looks during the training where we are learning the weights that maximizes the reward function.
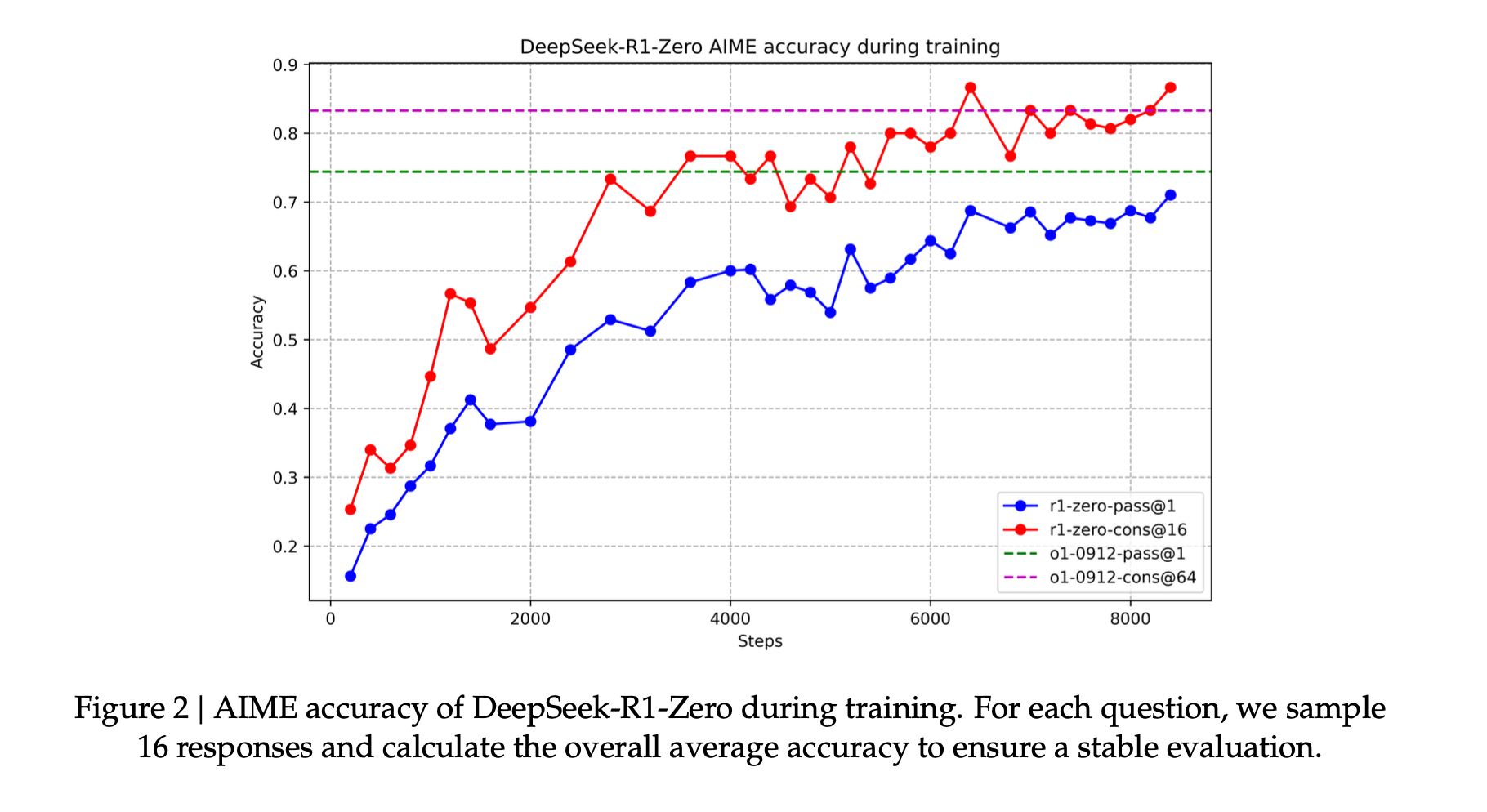
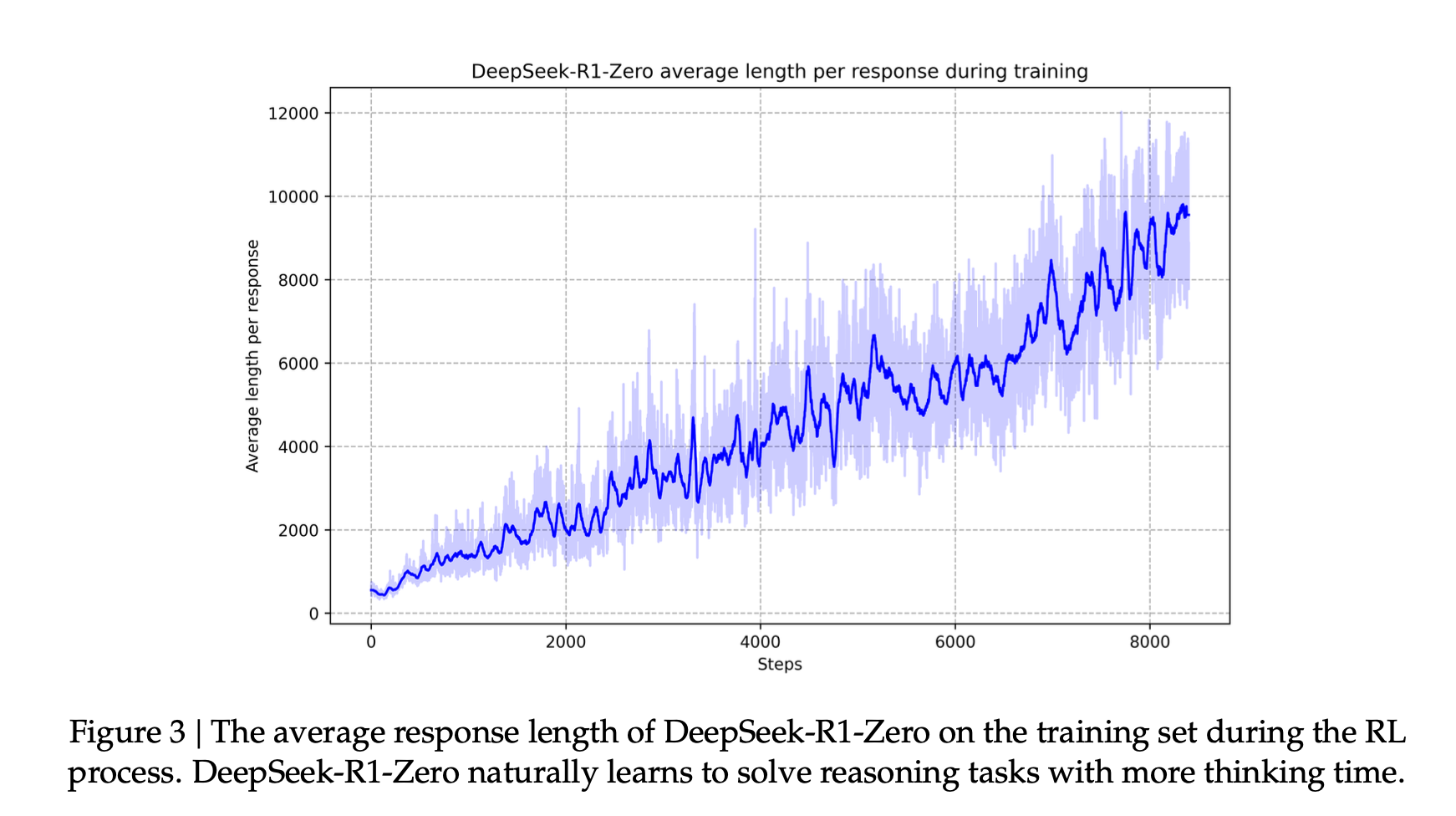
Another interesting aspect is the via using this kind of training framework, the reasoning ability emerges from the model, i.e., the model learns to reason and use it to generate a better response without being explicitly trained to do so. You see that by looking at the length of thinking response generated by the model as it trains.
Eventually, during the training, there emerges a AHA moment where the model uses this longer thinking response to actually generate a better response. Here's an example from the paper where the model uses the reasoning to generate a better response.

The R1 model build upon this idea but uses a bunch of other techniques (using SFT step with quality data with demonstrations of reasoning process], multi-stage training pipeline, mixture of reward models, etc.) to push the performance even further leading to a state of the art model.
Another interesting result that they shared is regarding distiallation - if you take the outputs of larger LLM and use only SFT to fine-tune the smaller LLM, it imbues a smaller LLM eg: Llama/Qwen 14/30/70B models with reasoning ability and improves their performance.
Closing thoughts
- If you have some model of the internet, how you use that model makes a difference. Right now, in LLMs the focus is immediate prediction given context (how Internet would respond to something), but ideally we want systems that can do more than just mimicking us. We want systems that can reason and push the frontier. RL allows us to find the move 37.